ELK学习
一、ELK介绍
1.ELK是什么?
ELK是三个开源软件的缩写
E: elasticsearch java 收集、分析、存储数据
L:logstash java 收集、分析、过滤日志文件数据
K: kibana java 提供web页面
F:filebeat go 负责收集日志文件
2.ELK经常用来做什么
1.收集:收集所有的日志数据
2.传输:能稳定的把所有的日志数据传输到ES
3.存储:ES能有效快速的存储日志数据
4.分析:可以通过web页面将数据展示分析
5.警告:提供错误报告,监控
3.ELK优点
1.处理方式灵活:elasticsearch是实时全文索引,具有强大的搜索功能
2.配置相对简单:elasticsearch全部使用JSON 接口,logstash使用模块配置,kibana的配置文件部分更简单。
3.检索性能高效:基于优秀的设计,虽然每次查询都是实时,但是也可以达到百亿级数据的查询秒级响应。
4.集群线性扩展:elasticsearch和logstash都可以灵活线性扩展
5.前端操作绚丽:kibana的前端设计比较绚丽,而且操作简单
4.日志收集、分析需求
1.web服务日志(nginx、tomcat)
2.系统日志
1.统计来源IP数量
2.统计访问次数最多排名前十的用户地址
3.站点被访问次数最多的URL
4.查询一上午 以上三个数据 的量
5.查询一下午 以上三个数据 的量
6.对比上午和下午的数据,对比昨天和今天的数据
二、ELK搭建
1.ES搭建
2.logstash搭建
1)安装java环境
[root@m01 ~]
[root@m01 ~]
[root@redis01 ~]
java version "1.8.0_181"
Java(TM) SE Runtime Environment (build 1.8.0_181-b13)
Java HotSpot(TM) 64-Bit Server VM (build 25.181-b13, mixed mode)
2)时间同步
[root@m01 ~]
3)安装logstash
[root@m01 ~]
[root@m01 ~]
[root@m01 ~]
[root@m01 ~]
3.logstash介绍
1)Logstash输入输出插件介绍
INPUT插件:使Logstash能够读取特定的事件源。
OUTPUT插件:将事件数据发送到特定的目的地,OUTPUT是事件流水线中的最后阶段。
|
|
|
| INPUT支持事件源 |
OUTPUT支持输出源 |
CODEC编解码器支持编码 |
| azure_event_hubs(微软云事件中心) |
elasticsearch(搜索引擎数据库) |
avro(数据序列化) |
| beats(filebeat日志收集工具) |
email(邮件) |
CEF(嵌入式框架) |
| elasticsearch(搜索引擎数据库) |
file(文件) |
es_bulk(ES中的bulk api) |
| file(文件) |
http(超文本传输协议) |
Json(数据序列化、格式化) |
| generator(生成器) |
kafka(基于java的消息队列) |
Json_lines(便于存储结构化) |
| heartbeat(高可用软件) |
rabbitmq(消息队列 OpenStack) |
line(行) |
| http_poller(http api) |
redis(缓存、消息队列、NoSQL) |
multiline(多行匹配) |
| jdbc(java连接数据库的驱动) |
s3*(存储) |
plain(纯文本,事件间无间隔) |
| kafka(基于java的消息队列) |
stdout(标准输出) |
rubydebug(ruby语法格式) |
| rabbitmq(消息队列 OpenStack) |
tcp(传输控制协议) |
|
| redis(缓存、消息队列、NoSQL) |
udp(用户数据报协议) |
|
| s3*(存储) |
|
|
| stdin(标准输入) |
|
|
| syslog(系统日志) |
|
|
| tcp(传输控制协议) |
|
|
| udp(用户数据报协议) |
|
2)Logstash输入输出插件测试
[root@m01 ~]
123
{
"@version" => "1",
"host" => "m01",
"message" => "123",
"@timestamp" => 2020-05-20T02:15:35.798Z
}
3)Logstash标准输入到文件
[root@m01 ~]
test output file
[INFO ] 2020-05-20 10:36:49.164 [[main]>worker0] file - Opening file {:path=>"/tmp/test_2020.05.141.log"}
[root@m01 ~]
-rw-r--r-- 1 root root 360 May 20 10:41 /tmp/test_2020.05.141.log
[root@m01 ~]
{"host":"m01","@timestamp":"2020-05-20T02:36:48.382Z","message":"","@version":"1"}
{"host":"m01","@timestamp":"2020-05-20T02:38:29.233Z","message":"test output file","@version":"1"}
{"host":"m01","@timestamp":"2020-05-20T02:39:19.797Z","message":"test2","@version":"1"}
4)Logstash标准输入到ES
[root@m01 ~]
test output es
[root@redis01 ~]
total 0
drwxr-xr-x 4 elasticsearch elasticsearch 29 May 20 08:30 amwRy5GTSzuhYxO8umPaIg
drwxr-xr-x 6 elasticsearch elasticsearch 47 May 20 10:52 AOn5lNnJRwGKVROOWbs1cA
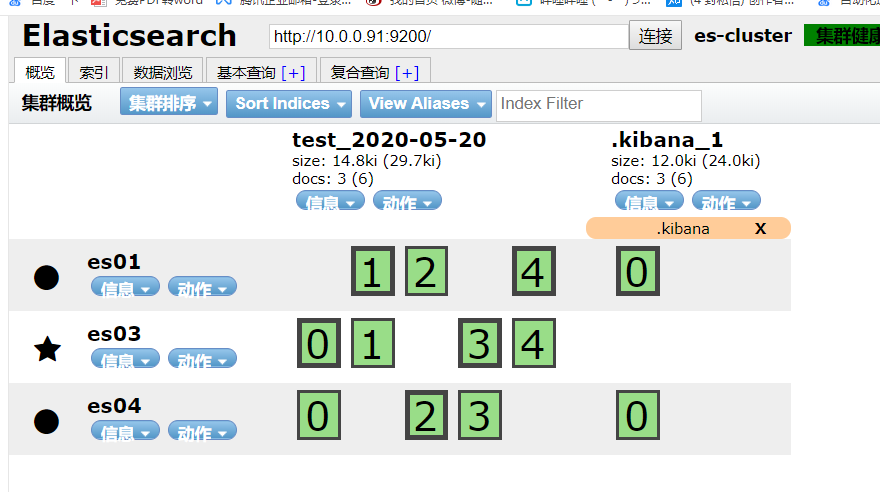
4.部署kibana
1)安装java
2)安装kibana
3)kibana页面
1> 时间区域
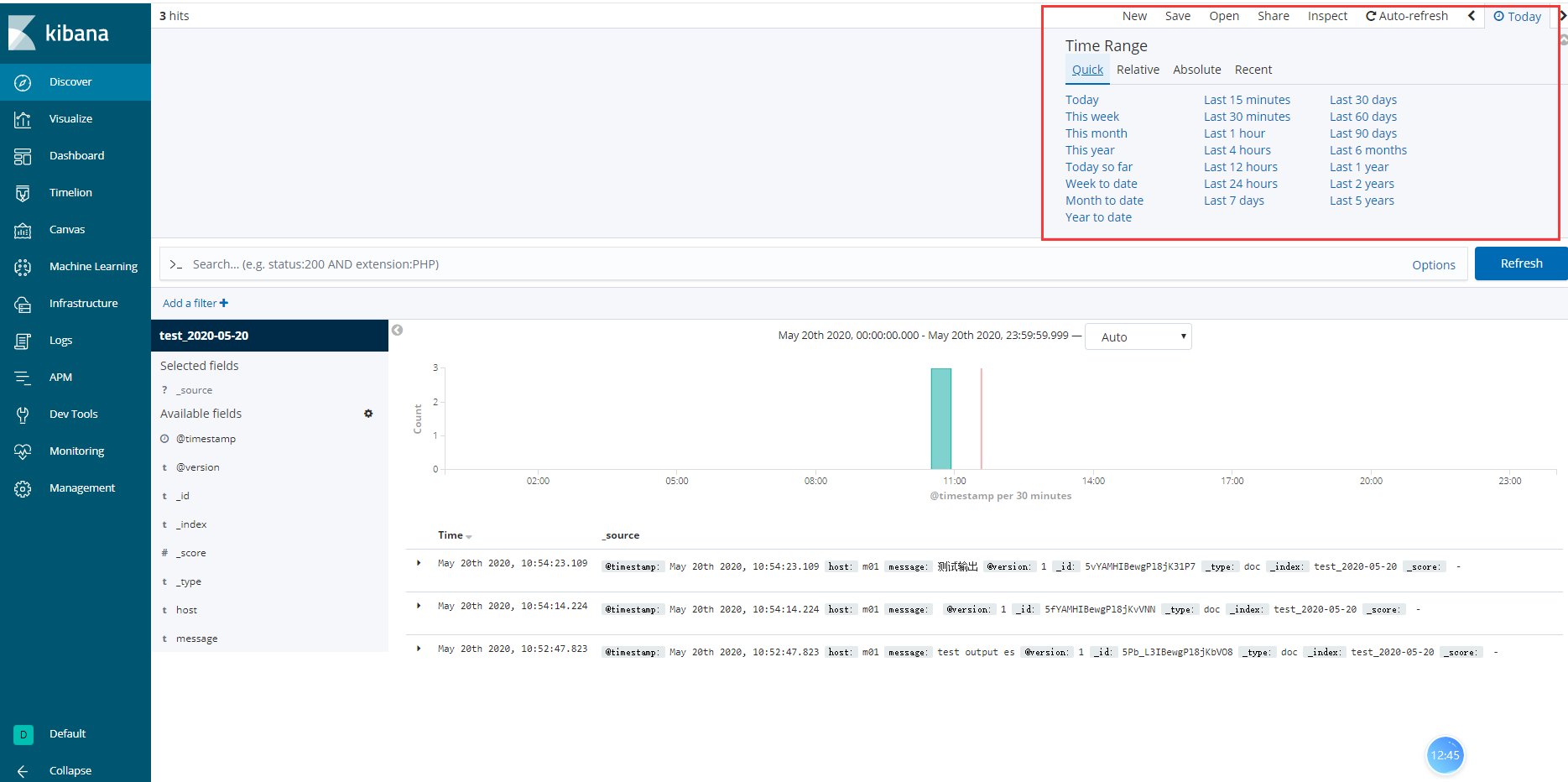
2> 日志列表区域
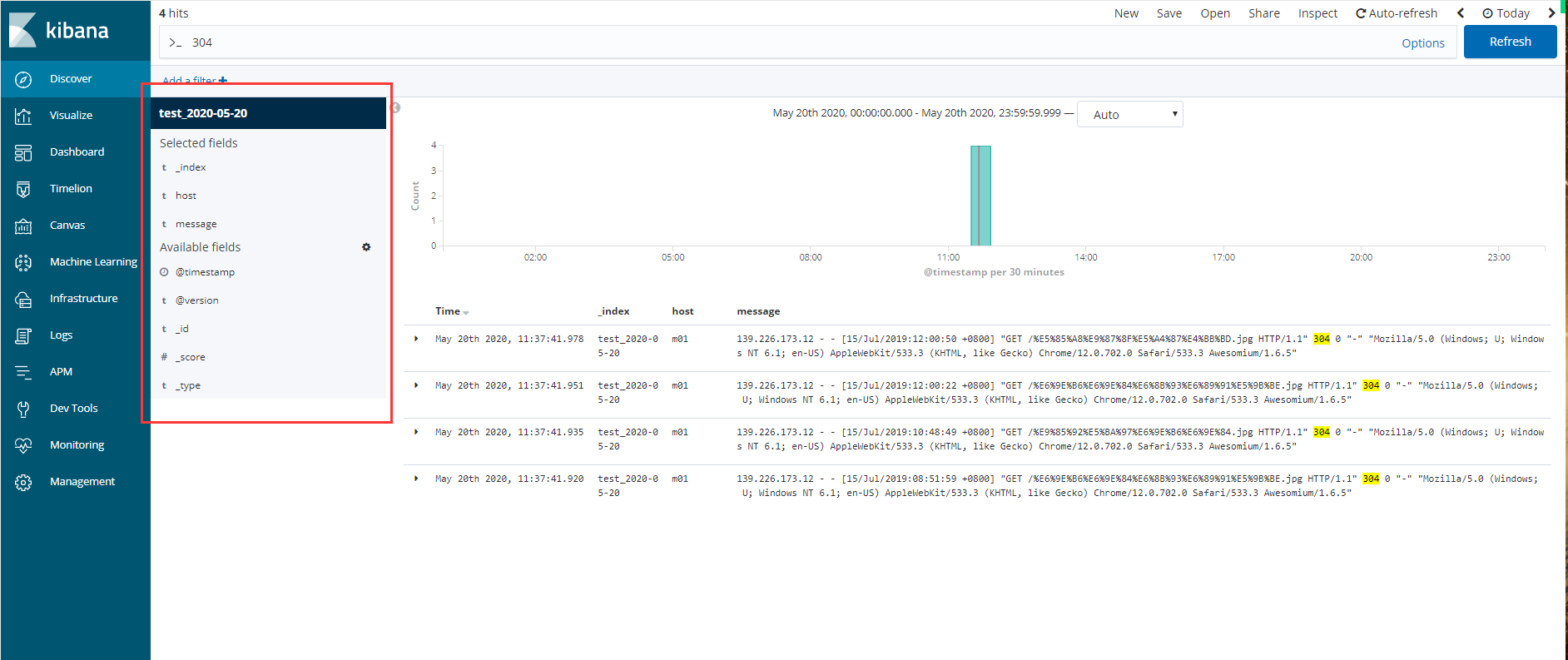
3>搜索区域
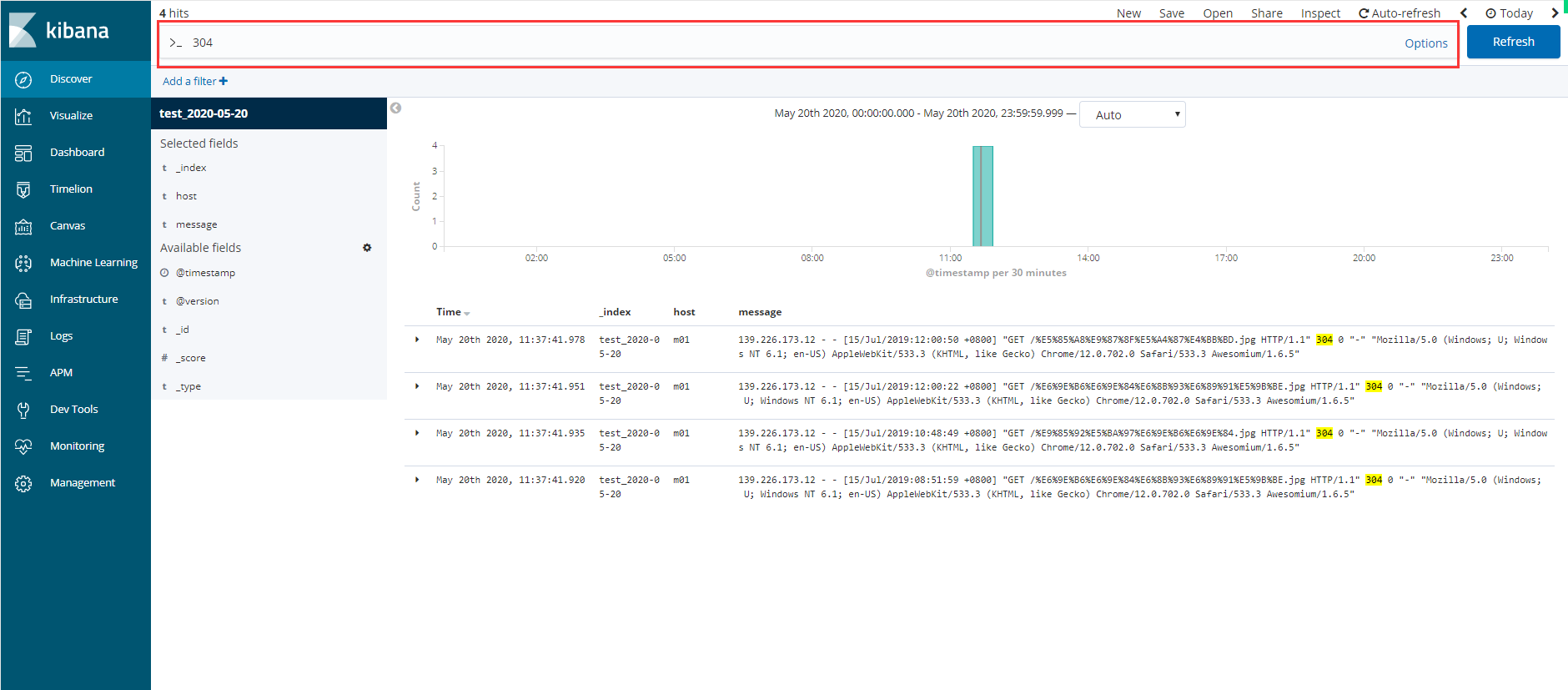
4> 数据展示区
三、Logstash使用
不难理解,我们的日志通常都是在日志文件中存储的,所以,当我们在使用INPUT插件时,收集日志,需要使用file模块,从文件中读取日志的内容,那么接下来讲解的是,将日志内容输出到另一个文件中,如此一来,我们可以将日志文件统一目录,方便查找。
注意:Logstash与其他服务不同,收集日志的配置文件需要我们根据实际情况自己去写。
前提:需要Logstash对被收集的日志文件有读的,并且对要写入的文件,有写入的权限。
1.logstash配置文件
[root@m01 ~]
[root@m01 ~]
path.config: /etc/logstash/conf.d
2.配置logstash收集文件中的日志到文件
1)配置logstash
[root@m01 ~]
input {
file {
type => "message-log"
path => "/var/log/messages"
start_position => "beginning"
}
}
output {
file {
path => "/tmp/message_%{+YYYY.MM.dd}.log"
}
}
2)启动logstash
[root@m01 ~]
Configuration OK
Validation Result: OK
[root@m01 ~]
3)测试日志收集
[root@m01 ~]
[root@m01 ~]
3.配置logstash收集文件中的日志到ES
1)配置logstash
[root@m01 ~]
input {
file {
type => "nginx-log"
path => "/var/log/nginx/access.log"
start_position => "beginning"
}
}
output {
elasticsearch {
hsots => ["ip地址"] index => "索引名称如:nginx_log"
}
}
2)启动
[root@m01 ~]