一、redis主从复制
1.主从复制原理
1.从库配置与主库同步
2.从库向主库发起SYNC命令
3.主库接收sync命令,执行bgsave,生成RDB文件
4.主库将RDB文件同步到从库
5.主库写入和传输RDB文件的时候,将新写入的数据放入缓冲区
6.从库接收到主库的RDB文件,先清空自己的数据
7,从库同步RDB中的数据
8.主库将缓冲区的命令传给从库
9.实现同步
2.redis主从实践
1)准备环境
| 角色 |
主机 |
IP |
端口 |
| 主库 |
redis01 |
172.16.1.91 |
6379 |
| 从库 |
redis02 |
172.16.1.92 |
6379 |
| 从库 |
redis03 |
172.16.1.93 |
6379 |
2)配置主从
1.登录三台主机查看redis主从信息
[root@redis01 ~]
127.0.0.1:6379> info replication
role:master
connected_slaves:0
master_repl_offset:0
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
2.如果主库有密码,主从同步时,从库需要加配置
masterauth 123
3.连接从库执行同步
127.0.0.1:6379> SLAVEOF 172.16.1.91 6379
OK
4.查看主库和从库的主从状态
[root@redis01 ~]
127.0.0.1:6379> info replication
role:master
connected_slaves:2
slave0:ip=172.16.1.92,port=6379,state=online,offset=43,lag=0
slave1:ip=172.16.1.93,port=6379,state=online,offset=43,lag=0
127.0.0.1:6379> info replication
role:slave
master_host:172.16.1.91
master_port:6379
master_link_status:up
master_last_io_seconds_ago:5
3)如果主库出现故障
1.模拟故障,关闭主库
2.主库查看状态
127.0.0.1:6379> info replication
role:slave
master_host:172.16.1.91
master_port:6379
master_link_status:down
master_last_io_seconds_ago:-1
3.选择一台机器,取消从库的主从
127.0.0.1:6379> SLAVEOF no one
OK
127.0.0.1:6379> info replication
role:master
connected_slaves:0
master_repl_offset:0
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
4.将其他从库指向 新的主库
127.0.0.1:6379> SLAVEOF 172.16.1.92 6379
OK
127.0.0.1:6379> info replication
role:slave
master_host:172.16.1.92
master_port:6379
master_link_status:up
master_last_io_seconds_ago:1
二、redis的高可用 sentinel 介绍
1. sentinel 介绍
Redis-Sentinel是Redis官方推荐的高可用性(HA)解决方案,当用Redis做Master-slave的高可用方案时,假如master宕机了,Redis本身(包括它的很多客户端)都没有实现自动进行主备切换,而Redis-sentinel本身也是一个独立运行的进程,它能监控多个master-slave集群,发现master宕机后能进行自动切换。
他必须基于redis主从
2.sentinel构造
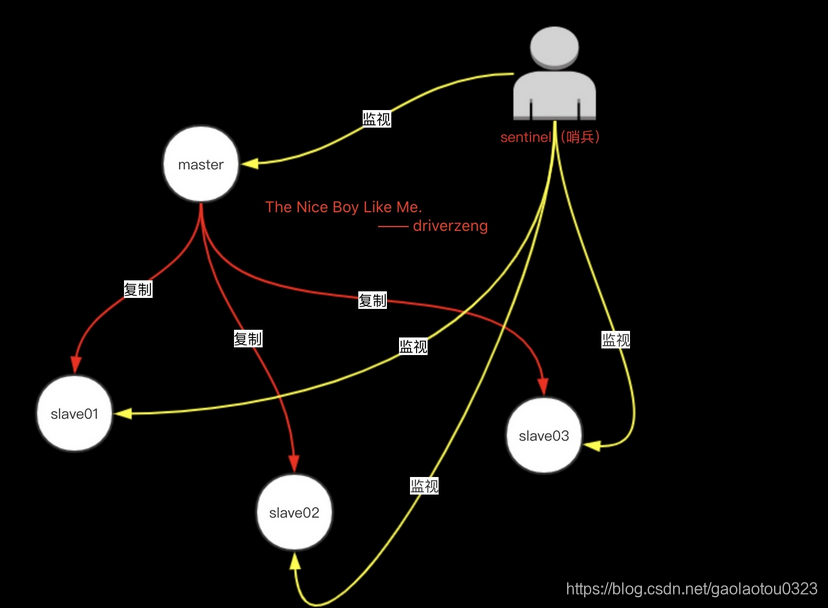
3.sentinel功能
1.监控(Monitoring):
Sentinel会不断地检查你的主服务器和从服务器是否运作正常。
2.提醒(Notification):
当被监控的某个Redis服务器出现问题时,Sentinel可以通过API向管理员或者其他应用程序发送通知。
3.自动故障迁移(Automatic failover):
当一个主服务器不能正常工作时,Sentinel会开始一次自动故障迁移操作,它会将失效主服务器的其中一个从服务器升级为新的主服务器,并让失效主服务器的其他从服务器改为复制新的主服务器;当客户端试图连接失效的主服务器时,集群也会向客户端返回新主服务器的地址,使得集群可以使用新主服务器代替失效服务器。
4.sentinel工作
1.Sentinel通过用户给定的配置文件来发现主服务器
2.Sentinel会与被监视的主服务器创建两个网络连接:
命令连接用于向主服务器发送命令。
订阅连接用于订阅指定的频道,从而发现监视同一主服务器的其他Sentinel。
3.Sentinel通过向主服务器发送INFO命令来自动获得所有从服务器的地址。
4.发现其他sentinel
5.Sentinel之间只会互相创建命令连接,用于进行通信。
6.检测实例的状态:Sentinel使用PING命令来检测实例的状态:如果实例在指定的时间内没有返回回复,或者返回错误的回复,那么该实例会被 Sentinel 判断为下线。
5.故障转移流程
1)发现主服务器已经进入客观下线状态。
2)基于Raft leader election协议 ,进行投票选举
3)如果当选失败,那么在设定的故障迁移超时时间的两倍之后,重新尝试当选。如果当选成功,那么执行以下步骤。
4)选出一个从服务器,并将它升级为主服务器。
5)向被选中的从服务器发送 SLAVEOF NO ONE 命令,让它转变为主服务器。
6)通过发布与订阅功能,将更新后的配置传播给所有其他Sentinel,其他Sentinel对它们自己的配置进行更新。
7)向已下线主服务器的从服务器发送SLAVEOF命令,让它们去复制新的主服务器。
8)当所有从服务器都已经开始复制新的主服务器时, leader Sentinel 终止这次故障迁移操作。
每当一个Redis实例被重新配置(reconfigured)—— 无论是被设置成主服务器、从服务器、又或者被设置成其他主服务器的从服务器 —— Sentinel 都会向被重新配置的实例发送一个CONFIG REWRITE命令,从而确保这些配置会持久化在硬盘里。
6.sentinel选择主库的规则
1)在失效主服务器属下的从服务器当中,那些被标记为主观下线、已断线、或者最后一次回复PING命令的时间大于五秒钟的从服务器都会被淘汰。
2)在失效主服务器属下的从服务器当中,那些与失效主服务器连接断开的时长超过down-after选项指定的时长十倍的从服务器都会被淘汰。
3)在经历了以上两轮淘汰之后剩下来的从服务器中,我们选出复制偏移量(replication offset)最大的那个从服务器作为新的主服务器;如果复制偏移量不可用,或者从服务器的复制偏移量相同,那么带有最小运行ID的那个从服务器成为新的主服务器。
三、sentinel实战
1.环境准备
| 角色 |
主机 |
IP |
端口 |
| 主库 |
redis01 |
172.16.1.91 |
6379 |
| 从库 |
redis02 |
172.16.1.92 |
6379 |
| 从库 |
redis03 |
172.16.1.93 |
6379 |
2.恢复三台主机的主从状态
127.0.0.1:6379> info replication
role:master
connected_slaves:2
slave0:ip=172.16.1.93,port=6379,state=online,offset=6091,lag=0
slave1:ip=172.16.1.91,port=6379,state=online,offset=6091,lag=0
master_repl_offset:6091
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:2
repl_backlog_histlen:6090
3.配置sentinel
[root@redis01 ~]
[root@redis01 ~]
daemonize yes
bind 172.16.1.91 127.0.0.1
port 26379
pidfile /server/redis/26379/redis.pid
logfile /server/redis/26379/redis.log
dir /server/redis/26379
sentinel monitor mymaster 172.16.1.92 6379 1
sentinel down-after-milliseconds mymaster 5000
sentinel failover-timeout mymaster 180000
sentinel parallel-syncs mymaster 1
4.启动sentinel
[root@redis01 ~]
5.停止sentinel
[root@redis01 ~]
6.测试sentinel
[root@redis02 ~]
[root@redis01 ~]
127.0.0.1:6379> info replication
role:master
connected_slaves:1
slave0:ip=172.16.1.93,port=6379,state=online,offset=997,lag=1
master_repl_offset:997
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:2
repl_backlog_histlen:996
[root@redis03 ~]
127.0.0.1:6379> info replication
role:slave
master_host:172.16.1.91
master_port:6379
master_link_status:up
master_last_io_seconds_ago:0
[root@redis02 ~]
[root@redis02 ~]
127.0.0.1:6379>
127.0.0.1:6379> info replication
role:slave
master_host:172.16.1.91
master_port:6379
master_link_status:up
master_last_io_seconds_ago:1
127.0.0.1:6379> info replication
role:master
connected_slaves:2
slave0:ip=172.16.1.93,port=6379,state=online,offset=12917,lag=0
slave1:ip=172.16.1.92,port=6379,state=online,offset=12917,lag=0
master_repl_offset:12917
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:2
repl_backlog_histlen:12916
7.sentinel管理命令
[root@redis01 ~]
127.0.0.1:26379> PING
PONG
127.0.0.1:26379> SENTINEL masters
127.0.0.1:26379> SENTINEL slaves mymaster
127.0.0.1:26379> SENTINEL get-master-addr-by-name mymaster
1) "172.16.1.91"
2) "6379"
127.0.0.1:26379> SENTINEL failover mymaster
OK
127.0.0.1:6379> CONFIG GET slave-priority
1) "slave-priority"
2) "100"
127.0.0.1:6379> CONFIG set slave-priority 0
OK
五、Redis Cluster 分布式集群介绍
1.什么是Redis Cluster
1.Redis集群是一个可以在多个Redis节点之间进行数据共享的设施(installation)。
2.Redis集群不支持那些需要同时处理多个键的Redis命令,因为执行这些命令需要在多个Redis节点之间移动数据,并且在高负载的情况下,这些命令将降低Redis集群的性能,并导致不可预测的行为。
3.Redis集群通过分区(partition)来提供一定程度的可用性(availability):即使集群中有一部分节点失效或者无法进行通讯,集群也可以继续处理命令请求。
4.Redis集群有将数据自动切分(split)到多个节点的能力。
2.Redis Cluster的特点
1.解决了redis资源利用率低下的问题
2.将数据平均分配到各个节点
3.如果客户端当时连接的节点不是将来要存储的分片节点,分片集群会将客户端连接切换至真正存储节点进行数据存储
4.在搭建集群时,会为每一个分片的主节点,对应一个从节点,实现slaveof功能,同时当主节点down,实现类似于sentinel的自动failover的功能。
3.槽的概念
1.在集群中,会把所有节点分为16384个槽位
2.槽位序号 0-16383 ,序号不重要,数量才重要
3.每一个槽位获取数据的概率是一样的
4.Redis Cluster故障转移
1.在集群里面,节点会对其他节点进行下线检测。
2.当一个主节点下线时,集群里面的其他主节点负责对下线主节点进行故障移。
3.换句话说,集群的节点集成了下线检测和故障转移等类似 Sentinel 的功能。
4.因为 Sentinel 是一个独立运行的监控程序,而集群的下线检测和故障转移等功能是集成在节点里面的,它们的运行模式非常地不同,所以尽管这两者的功能很相似,但集群的实现没有重用 Sentinel 的代码。
六、redis集群的搭建
1.环境准备
| 节点 |
IP |
端口 |
| 节点1 |
172.16.1.91 |
6380,6381 |
| 节点2 |
172.16.1.92 |
6380,6381 |
| 节点3 |
172.16.1.93 |
6380,6381 |
2.搭建redis集群
[root@redis01 ~]
[root@redis01 ~]
[root@redis01 ~]
[root@redis01 ~]
daemonize yes
bind 172.16.1.91 127.0.0.1
port 6380
pidfile /server/redis/6380/redis.pid
logfile /server/redis/6380/redis.log
dir /server/redis/6380
cluster-enabled yes
cluster-config-file cluster.conf
cluster-node-timeout 5000
[root@redis01 ~]
[root@redis01 ~]
[root@redis01 ~]
[root@redis01 ~]
[root@redis02 ~]
[root@redis03 ~]
3.启动所有节点的redis
[root@redis01 ~]
[root@redis01 ~]
[root@redis01 ~]
root 28053 1 0 12:21 ? 00:00:00 redis-server 172.16.1.91:6380 [cluster]
root 28057 1 0 12:22 ? 00:00:00 redis-server 172.16.1.91:6381 [cluster]
root 28061 12025 0 12:23 pts/2 00:00:00 grep --color=auto redis
4.关联所有的redis节点
[root@redis02 ~]
127.0.0.1:6380> CLUSTER NODES
12fb18db6787ce1f285d62a9e7faff7d17386bc3 :6380 myself,master - 0 0 0 connected
[root@redis01 ~]
127.0.0.1:6381> CLUSTER NODES
f4108be28fd2ae912e60b73efebdbbc05359dbc4 :6381 myself,master - 0 0 0 connected
127.0.0.1:6380> CLUSTER MEET 172.16.1.92 6380
OK
127.0.0.1:6380> CLUSTER MEET 172.16.1.92 6381
OK
127.0.0.1:6380> CLUSTER MEET 172.16.1.93 6380
OK
127.0.0.1:6380> CLUSTER MEET 172.16.1.93 6381
OK
127.0.0.1:6380> CLUSTER MEET 172.16.1.91 6381
OK
127.0.0.1:6380> CLUSTER NODES
12fb18db6787ce1f285d62a9e7faff7d17386bc3 172.16.1.92:6380 master - 0 1589352255870 2 connected
3acc954482623fa28222d42afceccb326627ffbe 172.16.1.93:6380 master - 0 1589352255366 4 connected
b4c268949dc32a7fae6eb6e76385e61372baa2d6 172.16.1.91:6380 myself,master - 0 0 1 connected
cacb696f16807eddd050842ea11a4526a712ca8e 172.16.1.92:6381 master - 0 1589352256876 3 connected
f4108be28fd2ae912e60b73efebdbbc05359dbc4 172.16.1.91:6381 master - 0 1589352256372 0 connected
79f60ba8f70d0366d041038296ace2d4dfc54847 172.16.1.93:6381 master - 0 1589352256674 5 connected
127.0.0.1:6380> CLUSTER INFO
cluster_state:fail
cluster_slots_assigned:0
cluster_slots_ok:0
cluster_slots_pfail:0
cluster_slots_fail:0
cluster_known_nodes:6
cluster_size:0
cluster_current_epoch:5
cluster_my_epoch:1
cluster_stats_messages_sent:1583
cluster_stats_messages_received:1583
5.分配槽位
redis01: 5462 个槽位 (0-5461)
redis02: 5461 个槽位 (5462-10922)
redis03: 5461 个槽位 (10923-16383)
[root@redis01 ~]
OK
[root@redis01 ~]
OK
[root@redis01 ~]
OK
127.0.0.1:6380> CLUSTER NODES
12fb18db6787ce1f285d62a9e7faff7d17386bc3 172.16.1.92:6380 master - 0 1589353111614 2 connected 5462-10922
3acc954482623fa28222d42afceccb326627ffbe 172.16.1.93:6380 master - 0 1589353112620 4 connected 10923-16383
b4c268949dc32a7fae6eb6e76385e61372baa2d6 172.16.1.91:6380 myself,master - 0 0 1 connected 0-5461
127.0.0.1:6380> CLUSTER INFO
cluster_state:ok
cluster_slots_assigned:16384
cluster_slots_ok:16384
cluster_slots_pfail:0
cluster_slots_fail:0
cluster_known_nodes:6
cluster_size:3
cluster_current_epoch:5
cluster_my_epoch:1
cluster_stats_messages_sent:7478
cluster_stats_messages_received:7478
6.插入数据测试
[root@redis01 ~]
127.0.0.1:6380> set k1 v1
(error) MOVED 12706 172.16.1.93:6380
[root@redis03 ~]
127.0.0.1:6380> set k1 v1
OK
[root@redis01 ~]
OK
[root@redis01 ~]
172.16.1.91:6380> set k1 v1
-> Redirected to slot [12706] located at 172.16.1.93:6380
OK
for i in {1..10000};do echo $i;redis-cli -c -h 172.16.1.91 -p 6380 set k_${i} v_{i};done
[root@redis01 ~]
127.0.0.1:6380> DBSIZE
(integer) 3343
[root@redis02 ~]
127.0.0.1:6380> DBSIZE
(integer) 3316
[root@redis03 ~]
127.0.0.1:6380> DBSIZE
(integer) 3341
7.添加主从为新的分片
[root@redis01 ~]
127.0.0.1:6380> CLUSTER NODES
12fb18db6787ce1f285d62a9e7faff7d17386bc3 172.16.1.92:6380 master - 0 1589356146737 2 connected 5462-10922
3acc954482623fa28222d42afceccb326627ffbe 172.16.1.93:6380 master - 0 1589356146737 4 connected 10923-16383
b4c268949dc32a7fae6eb6e76385e61372baa2d6 172.16.1.91:6380 myself,master - 0 0 1 connected 0-5461
cacb696f16807eddd050842ea11a4526a712ca8e 172.16.1.92:6381 master - 0 1589356147744 4 connected
f4108be28fd2ae912e60b73efebdbbc05359dbc4 172.16.1.91:6381 master - 0 1589356147240 2 connected
79f60ba8f70d0366d041038296ace2d4dfc54847 172.16.1.93:6381 master - 0 1589356146737 5 connected
[root@redis01 ~]
172.16.1.91:6381> CLUSTER REPLICATE 12fb18db6787ce1f285d62a9e7faff7d17386bc3
OK
[root@redis01 ~]
172.16.1.92:6381> CLUSTER REPLICATE 3acc954482623fa28222d42afceccb326627ffbe
OK
[root@redis01 ~]
172.16.1.93:6381> CLUSTER REPLICATE b4c268949dc32a7fae6eb6e76385e61372baa2d6
OK
127.0.0.1:6380> CLUSTER NODES
12fb18db6787ce1f285d62a9e7faff7d17386bc3 172.16.1.92:6380 master - 0 1589356146737 2 connected 5462-10922
3acc954482623fa28222d42afceccb326627ffbe 172.16.1.93:6380 master - 0 1589356146737 4 connected 10923-16383
b4c268949dc32a7fae6eb6e76385e61372baa2d6 172.16.1.91:6380 myself,master - 0 0 1 connected 0-5461
cacb696f16807eddd050842ea11a4526a712ca8e 172.16.1.92:6381 slave 3acc954482623fa28222d42afceccb326627ffbe 0 1589356147744 4 connected
f4108be28fd2ae912e60b73efebdbbc05359dbc4 172.16.1.91:6381 slave 12fb18db6787ce1f285d62a9e7faff7d17386bc3 0 1589356147240 2 connected
79f60ba8f70d0366d041038296ace2d4dfc54847 172.16.1.93:6381 slave b4c268949dc32a7fae6eb6e76385e61372baa2d6 0 1589356146737 5 connected
8.错误演示
[root@redis01 ~]
172.16.1.91:6380> shutdown
not connected> quit
[root@redis01 ~]
172.16.1.91:6381>
172.16.1.91:6381> shutdown
[root@redis02 ~]
127.0.0.1:6380> set k1 v1
-> Redirected to slot [12706] located at 172.16.1.93:6380
OK
172.16.1.93:6380> set k2 v2
-> Redirected to slot [449] located at 172.16.1.93:6381
OK
9.节点恢复
[root@redis01 ~]
[root@redis01 ~]
[root@redis01 ~]
172.16.1.91:6380>
172.16.1.91:6380> CLUSTER NODES
3acc954482623fa28222d42afceccb326627ffbe 172.16.1.93:6380 master - 0 1589356755404 4 connected 10923-16383
79f60ba8f70d0366d041038296ace2d4dfc54847 172.16.1.93:6381 master - 0 1589356753892 6 connected 0-5461
12fb18db6787ce1f285d62a9e7faff7d17386bc3 172.16.1.92:6380 master - 0 1589356753892 2 connected 5462-10922
f4108be28fd2ae912e60b73efebdbbc05359dbc4 172.16.1.91:6381 slave 12fb18db6787ce1f285d62a9e7faff7d17386bc3 0 1589356755404 2 connected
b4c268949dc32a7fae6eb6e76385e61372baa2d6 172.16.1.91:6380 myself,slave 79f60ba8f70d0366d041038296ace2d4dfc54847 0 0 1 connected
cacb696f16807eddd050842ea11a4526a712ca8e 172.16.1.92:6381 slave 3acc954482623fa28222d42afceccb326627ffbe 0 1589356754899 4 connected
172.16.1.91:6380>